Casi d'uso e applicazioni
L'annotazione audio è stata utilizzata da diversi settori per alcuni anni. Cominciamo con quello più ovvio: gli assistenti virtuali.
Assistenti virtuali
Formazione degli assistenti virtuali su vari set di dati con annotazioni audio per consentire lo sviluppo di un assistente vocale in grado di elaborare la richiesta in modo accurato e rispondere rapidamente per una migliore esperienza del cliente. Entro il 2020, un terzo delle famiglie britanniche e statunitensi aveva almeno un altoparlante intelligente con un assistente virtuale integrato.
Moduli di sintesi vocale
La tecnologia deve essere addestrata su file audio annotati per sviluppare un modulo di sintesi vocale in grado di convertire senza problemi il testo digitale in un linguaggio naturale.
chatbots
I chatbot sono parte integrante dell'assistenza clienti. I chatbot dovrebbero essere addestrati a interpretare le parole e le frasi degli utenti utilizzando file audio annotati per simulare a conversazione naturale con gli esseri umani.
Riconoscimento vocale automatico (ASR)
Si tratta di trascrivere le parole pronunciate in testo scritto. Lo stesso "riconoscimento vocale" si riferisce al processo di conversione delle parole pronunciate nel testo; tuttavia, il riconoscimento vocale e l'identificazione dell'oratore mirano a identificare sia il contenuto parlato che l'identità dell'oratore. La precisione dell'ASR è determinata da diversi parametri, ad es. volume dell'altoparlante, rumore di fondo, attrezzatura di registrazione e altro.
In che modo Shaip aiuta?
Se hai in mente un progetto di annotazione audio/vocale di prim'ordine, hai senza dubbio bisogno di un partner affidabile per l'etichettatura e l'annotazione. Se l'affidabilità e la precisione sono qualcosa che stai cercando, crediamo che Shaip sia il partner di cui hai bisogno.
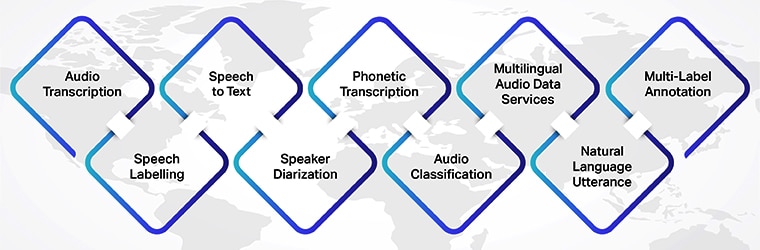
Shaip è stata in prima linea nei servizi di etichettatura e annotazione di audio, video e immagini sin dall'inizio. La nostra esperienza va oltre la fornitura di soluzioni di etichettatura vocale di base. Con annotatori altamente esperti e qualificati, abbiamo la larghezza di banda per fornire un grande volume di file audio annotati multilingue. I nostri servizi includono trascrizione audio, etichettatura vocale, sintesi vocale, diarizzazione degli altoparlanti, trascrizione fonetica, classificazione audio, servizi di dati audio multilingue, enunciato in linguaggio naturale, annotazione multietichetta.
Trascrizione audio
Aiutiamo a sviluppare modelli NLP di prim'ordine fornendo file audio accuratamente annotati per tutti i tipi di progetti. Permettiamo ai clienti di scegliere tra vari tipi e formati audio: formato standard, trascrizione letterale e non letterale.
Etichettatura del discorso
Gli esperti di Shaip separano i suoni nel registrazione audio ed etichetta ogni file. Questa tecnica prevede l'identificazione di suoni simili in un file audio, la loro separazione e l'annotazione accurata per lo sviluppo dati di allenamento.
Discorso al testo
La sintesi vocale è una parte fondamentale dello sviluppo del modello NLP. Con questa tecnica, il parlato registrato viene convertito in testo. Quindi, è importante concentrarsi sulla pronuncia, sulle parole e sulle frasi nei vari dialetti.
Diarizzazione dei relatori
Nella diarizzazione degli altoparlanti, il file audio viene partizionato in diversi segmenti audio in base alla sorgente sonora. I confini dei parlanti sono identificati e classificati in segmenti per determinare il numero totale di parlanti. Le sorgenti includono rumore di fondo, musica, silenzio e altro.
Trascrizione fonetica
I nostri servizi di trascrizione fonetica sono molto ricercati dai partner tecnologici. Eccelliamo nel convertire l'audio in parole specifiche usando i simboli fonetici.
Classificazione audio
Il nostro team di esperti di annotatori classifica la registrazione audio in categorie preimpostate. Alcune categorie includono rumore di fondo, intento dell'utente, numero di parlanti, segmentazione semantica e altro.
Servizi di dati audio multilingue
È un altro servizio altamente preferito di Shaip. Poiché disponiamo di un gruppo eterogeneo di annotatori qualificati, siamo in grado di fornire risultati eccellenti annotazione vocale servizi per diverse lingue e dialetti.
Espressione in linguaggio naturale
Le espressioni in linguaggio naturale sono adatte per addestrare chatbot o assistenti virtuali per aiutare ad annotare i minimi dettagli discorso umano, come stress, dialetti, semantica e contesto.
Annotazione multietichetta
Un singolo file audio può appartenere a più classi e, in quanto tale, è importante fornire annotazioni multi-etichetta per aiutare i modelli ML a differenziare tra due sorgenti audio.