


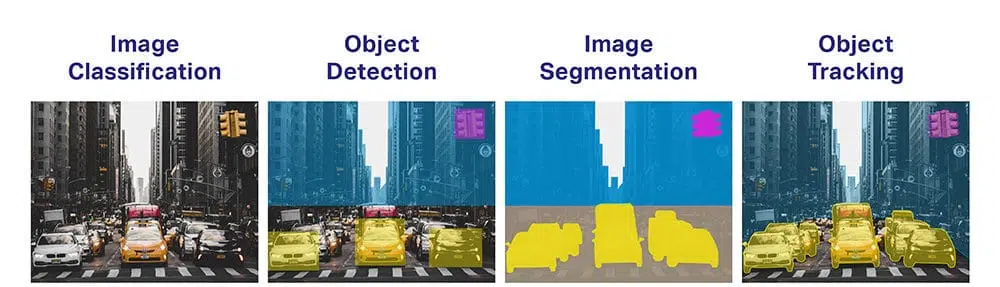
- Classificazione degli oggetti: Quale ampia categoria di oggetti ci sono?
- Identificazione dell'oggetto: Che tipo di un dato oggetto ci sono?
- Verifica dell'oggetto: Qual è l'oggetto nella fotografia?
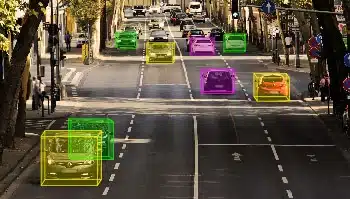
- Rilevamento di oggetti: Dove sono gli oggetti nella fotografia?
- Rilevamento del punto di riferimento dell'oggetto: Quali sono i punti chiave dell'oggetto nella fotografia?
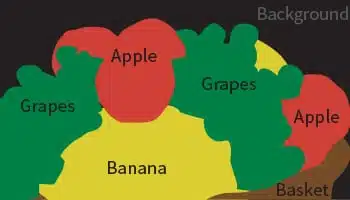
- Segmentazione degli oggetti: Quali pixel appartengono all'oggetto nell'immagine?
- Riconoscimento oggetto: Quali oggetti ci sono in questa fotografia e dove sono?

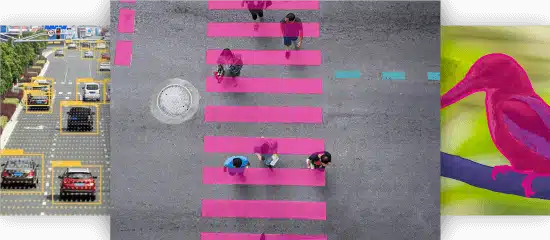


Raccolta di immagini

Raccolta video

Scatole di delimitazione
Cuboidi 3D
Segmentazione semantica

Annotazione poligonale

Annotazione punto di riferimento

Segmentazione della linea

Trascrizione dell'immagine
Video Trascrizione

Classificazione delle immagini
Segmentazione dell'immagine

Annotazione del punto chiave dell'immagine

Classificazione video
Segmentazione video

- Caso d'uso: Modello ADAS per auto
- Formato: Immagini
- Volume: 455,000+
- Annotazione: Non

- Caso d'uso: Rilevamento dei punti di riferimento
- Formato: Immagini
- Volume: 80,000+
- Annotazione: Non

- Caso d'uso: Monitoraggio dei pedoni
- Formato: Video
- Volume: 84,500+
- Annotazione: Sì

- Caso d'uso: Riconoscimento alimentare
- Formato: Immagini
- Volume: 55,000+
- Annotazione: Sì

AI sanitari
Addestra i modelli ML per rilevare i nei tumorali nelle immagini della pelle o per trovare sintomi nelle scansioni MRI o nei raggi X del paziente.

Riconoscimento facciale
Addestra i modelli ML per identificare le immagini delle persone in base alle caratteristiche facciali e confrontarle con un database di profili facciali per rilevare e taggare le persone.

Applicazioni geospaziali
Annotazione di immagini satellitari e fotografia UAV per preparare set di dati per il geoprocessing e annotare la nuvola di punti 3D per Geo.AI.

Realtà aumentata (RA)
Con l'auricolare AR, posiziona oggetti virtuali nel mondo reale. Può rilevare superfici piane come pareti, tavoli e pavimenti, una parte molto critica per stabilire profondità e dimensioni e posizionare oggetti virtuali nel mondo fisico.

Auto a guida autonoma
Più telecamere acquisiscono video da un'angolazione diversa per identificare i confini di segnali stradali, strade, automobili, oggetti e pedoni nelle vicinanze per addestrare le auto a guida autonoma a sterzare automaticamente il veicolo ed evitare di colpire gli ostacoli mentre guida il passeggero in sicurezza.

Commercio al dettaglio/e-commerce
Con la visione artificiale nella vendita al dettaglio, le applicazioni possono offrire consigli personalizzati basati sui modelli di acquisto dei clienti e accelerare le operazioni aziendali come la gestione degli scaffali, i pagamenti, ecc.




Persone
Team dedicati e formati:
- Oltre 30,000 collaboratori per la creazione di dati, l'etichettatura e il controllo qualità
- Team di gestione del progetto con credenziali
- Team di sviluppo prodotto esperto
- Talent Pool Sourcing & Onboarding Team

Processo
La massima efficienza del processo è assicurata da:
- Robusto processo Stage-Gate 6 Sigma
- Un team dedicato di cinture nere 6 Sigma: titolari di processi chiave e conformità alla qualità
- Miglioramento continuo e ciclo di feedback

Piattaforma
La piattaforma brevettata offre vantaggi:
- Piattaforma end-to-end basata sul web
- Qualità impeccabile
- TAT . più veloce
- Consegna senza soluzione di continuità
Persone
Team dedicati e formati:
- Oltre 30,000 collaboratori per la creazione di dati, l'etichettatura e il controllo qualità
- Team di gestione del progetto con credenziali
- Team di sviluppo prodotto esperto
- Talent Pool Sourcing & Onboarding Team
Processo
La massima efficienza del processo è assicurata da:
- Robusto processo Stage-Gate 6 Sigma
- Un team dedicato di cinture nere 6 Sigma: titolari di processi chiave e conformità alla qualità
- Miglioramento continuo e ciclo di feedback
Piattaforma
La piattaforma brevettata offre vantaggi:
- Piattaforma end-to-end basata sul web
- Qualità impeccabile
- TAT . più veloce
- Consegna senza soluzione di continuità