



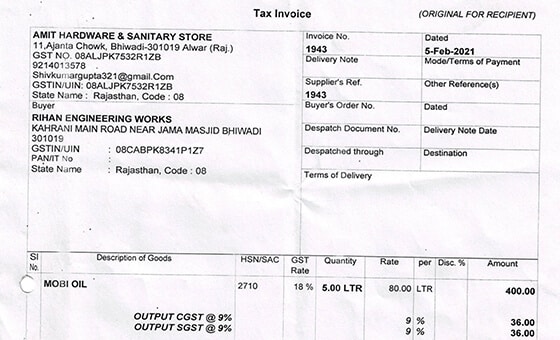






- Caso d'uso: Modello di riconoscimento degli oggetti
- Formato: Video
- Volume: 5,000+
- Annotazione: Non

- Caso d'uso: doc. Modello di riconoscimento
- Formato: Immagini
- Volume: 15,900+
- Annotazione: Non
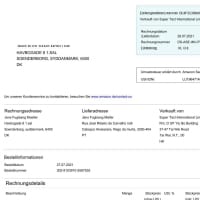
- Caso d'uso: Riconoscimento fattura Modello
- Formato: Immagini
- Volume: 45,000+
- Annotazione: Non

- Caso d'uso: No. Riconoscimento targa
- Formato: Immagini
- Volume: 3,500+
- Annotazione: Non

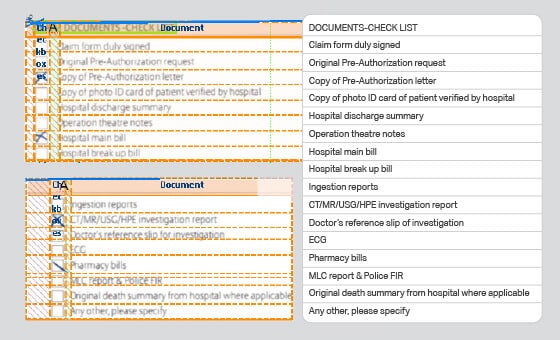
- Caso d'uso: Modello OCR
- Formato: Immagini
- Volume: 90,000+
- Annotazione: Sì

- Caso d'uso: Modello OCR multilingue
- Formato: Immagini
- Volume: 23,500+
- Annotazione: Sì
- Caso d'uso: Modello di rilevamento degli oggetti
- Formato: Immagini
- Volume: 11,500+
- Annotazione: Non

- Caso d'uso: Ricevi modelli AI
- Formato: Immagini
- Volume: 75,000+
- Annotazione: Non

Persone
Team dedicati e formati:
- Oltre 30,000 collaboratori per raccolta dati, etichettatura e QA
- Team di gestione del progetto con credenziali
- Team di sviluppo prodotto esperto
- Talent Pool Sourcing & Onboarding Team

Processo
La massima efficienza del processo è assicurata da:
- Robusto processo Stage-Gate 6 Sigma
- Un team dedicato di cinture nere 6 Sigma: titolari di processi chiave e conformità alla qualità
- Miglioramento continuo e ciclo di feedback

Piattaforma
La piattaforma brevettata offre vantaggi:
- Piattaforma end-to-end basata sul web
- Qualità impeccabile
- TAT . più veloce
- Consegna senza soluzione di continuità



La creazione di PNL clinica è un'attività critica che richiede un'enorme esperienza di dominio per essere risolta. Vedo chiaramente che sei diversi anni avanti a Google in questo settore. Voglio lavorare con te e scalarti.
Google, Inc. Direttore
Il mio team di ingegneri ha lavorato con il team di Shaip per più di 2 anni durante lo sviluppo di API vocali per la sanità. Siamo rimasti colpiti dal loro lavoro svolto nella PNL specifica per l'assistenza sanitaria e da ciò che sono in grado di ottenere con set di dati complessi.
Google, Inc. Responsabile dell'ingegneria