

Cosa sono i modelli linguistici di grandi dimensioni?
I Large Language Models (LLM) sono sistemi avanzati di intelligenza artificiale (AI) progettati per elaborare, comprendere e generare testo simile a quello umano. Si basano su tecniche di deep learning e sono addestrati su enormi set di dati, che di solito contengono miliardi di parole provenienti da diverse fonti come siti Web, libri e articoli. Questa vasta formazione consente agli LLM di cogliere le sfumature della lingua, della grammatica, del contesto e persino di alcuni aspetti della cultura generale.
Alcuni LLM popolari, come GPT-3 di OpenAI, utilizzano un tipo di rete neurale chiamata trasformatore, che consente loro di gestire attività linguistiche complesse con notevole competenza. Questi modelli possono eseguire una vasta gamma di attività, come ad esempio:
- Rispondendo alle domande
- Testo riassuntivo
- Tradurre lingue
- Generazione di contenuti
- Anche impegnarsi in conversazioni interattive con gli utenti
Man mano che gli LLM continuano a evolversi, hanno un grande potenziale per migliorare e automatizzare varie applicazioni in tutti i settori, dal servizio clienti e dalla creazione di contenuti all'istruzione e alla ricerca. Tuttavia, sollevano anche preoccupazioni etiche e sociali, come il comportamento prevenuto o l'uso improprio, che devono essere affrontate man mano che la tecnologia avanza.

Esempi popolari di modelli linguistici di grandi dimensioni
Ecco alcuni esempi importanti di LLM ampiamente utilizzati in diversi settori verticali:
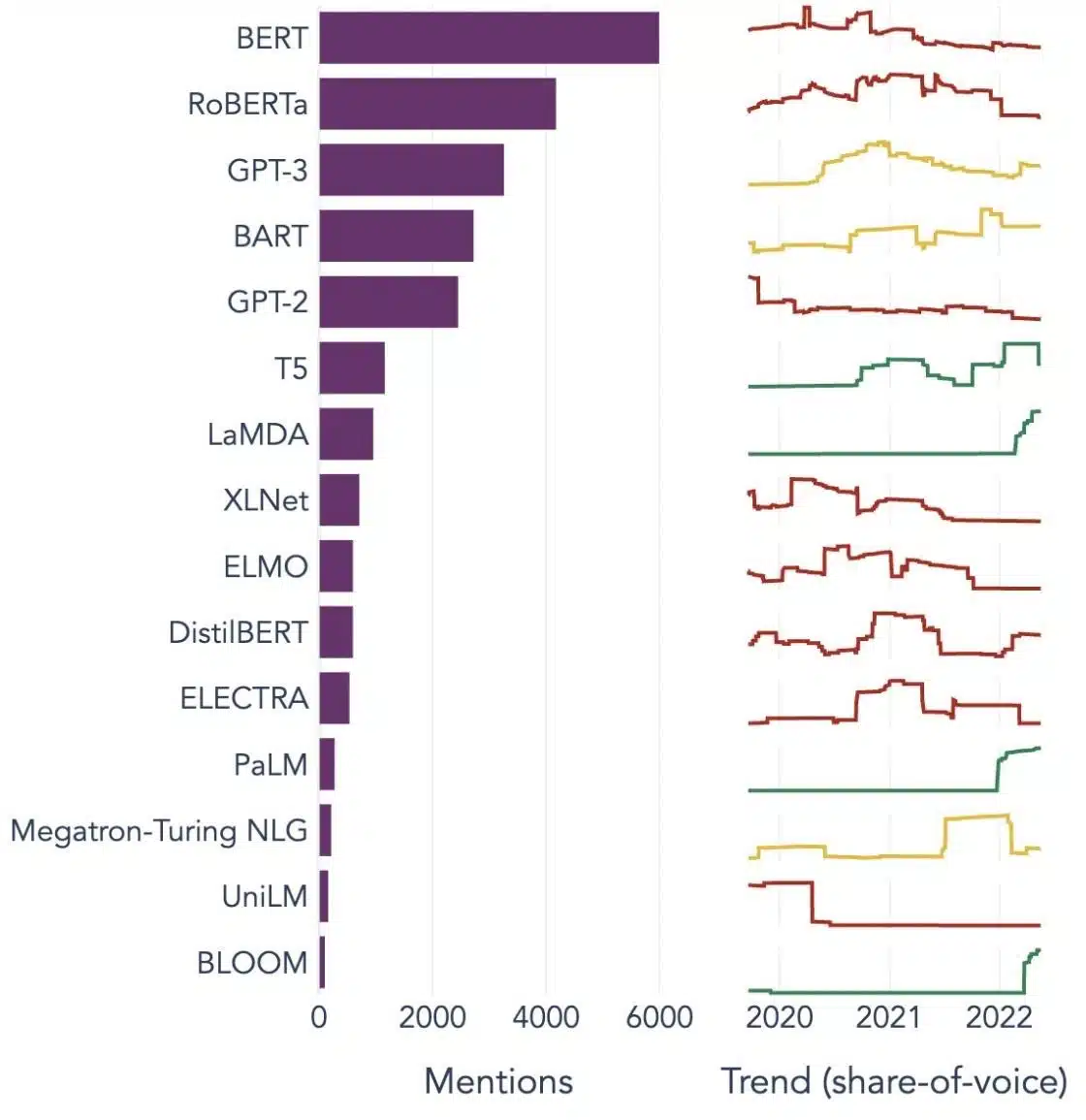
Image Source: Verso la scienza dei dati
Come vengono addestrati i modelli LLM?
La formazione di modelli linguistici di grandi dimensioni (LLM) è piuttosto un'impresa che comporta diversi passaggi cruciali. Ecco un resoconto semplificato e dettagliato del processo:
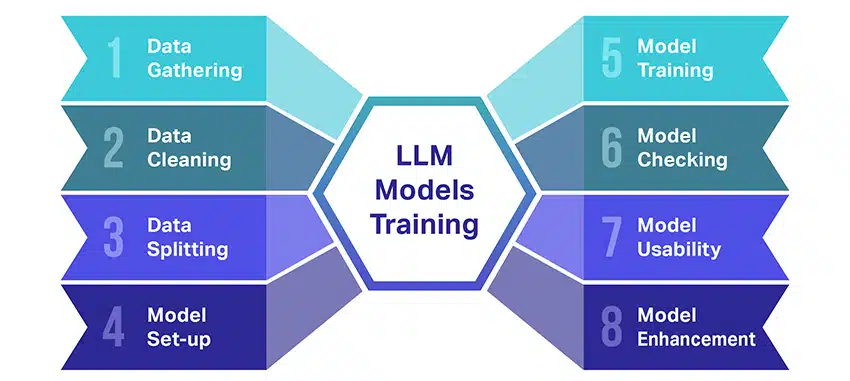
- Raccolta di dati testuali: La formazione di un LLM inizia con la raccolta di una grande quantità di dati di testo. Questi dati possono provenire da libri, siti Web, articoli o piattaforme di social media. L'obiettivo è catturare la ricca diversità del linguaggio umano.
- Pulizia dei dati: I dati di testo non elaborati vengono quindi riordinati in un processo chiamato preelaborazione. Ciò include attività come la rimozione di caratteri indesiderati, la suddivisione del testo in parti più piccole chiamate token e l'inserimento di tutto in un formato con cui il modello può funzionare.
- Divisione dei dati: Successivamente, i dati puliti vengono suddivisi in due set. Un set, i dati di addestramento, verrà utilizzato per addestrare il modello. L'altro set, i dati di convalida, verrà utilizzato successivamente per testare le prestazioni del modello.
- Impostazione del modello: Viene quindi definita la struttura del LLM, nota come architettura. Ciò comporta la selezione del tipo di rete neurale e la decisione su vari parametri, come il numero di livelli e le unità nascoste all'interno della rete.
- Formazione del modello: Ora inizia l'allenamento vero e proprio. Il modello LLM apprende osservando i dati di addestramento, effettuando previsioni basate su ciò che ha appreso finora e quindi regolando i suoi parametri interni per ridurre la differenza tra le sue previsioni e i dati effettivi.
- Controllo del modello: L'apprendimento del modello LLM viene verificato utilizzando i dati di convalida. Questo aiuta a vedere le prestazioni del modello e a modificare le impostazioni del modello per prestazioni migliori.
- Utilizzo del modello: Dopo la formazione e la valutazione, il modello LLM è pronto per l'uso. Ora può essere integrato in applicazioni o sistemi in cui genererà testo in base ai nuovi input forniti.
- Migliorare il modello: Infine, c'è sempre spazio per migliorare. Il modello LLM può essere ulteriormente perfezionato nel tempo, utilizzando dati aggiornati o regolando le impostazioni in base al feedback e all'utilizzo nel mondo reale.
Ricorda, questo processo richiede notevoli risorse computazionali, come potenti unità di elaborazione e spazio di archiviazione di grandi dimensioni, nonché conoscenze specializzate nell'apprendimento automatico. Ecco perché di solito viene svolto da organizzazioni o società di ricerca dedicate con accesso alle infrastrutture e alle competenze necessarie.
Il LLM si basa sull'apprendimento supervisionato o non supervisionato?
I modelli linguistici di grandi dimensioni vengono generalmente addestrati utilizzando un metodo chiamato apprendimento supervisionato. In termini semplici, ciò significa che imparano da esempi che mostrano loro le risposte corrette.
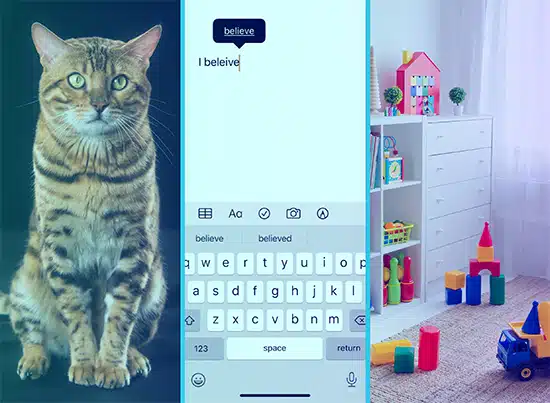 Immagina di insegnare a un bambino le parole mostrandogli delle immagini. Mostri loro l'immagine di un gatto e dici "gatto" e loro imparano ad associare quell'immagine alla parola. Ecco come funziona l'apprendimento supervisionato. Il modello riceve molto testo (le "immagini") e gli output corrispondenti (le "parole") e impara ad abbinarli.
Immagina di insegnare a un bambino le parole mostrandogli delle immagini. Mostri loro l'immagine di un gatto e dici "gatto" e loro imparano ad associare quell'immagine alla parola. Ecco come funziona l'apprendimento supervisionato. Il modello riceve molto testo (le "immagini") e gli output corrispondenti (le "parole") e impara ad abbinarli.
Quindi, se dai da mangiare a un LLM una frase, cerca di prevedere la parola o la frase successiva in base a ciò che ha appreso dagli esempi. In questo modo, impara a generare un testo che abbia senso e si adatti al contesto.
Detto questo, a volte gli LLM usano anche un po' di apprendimento senza supervisione. È come lasciare che il bambino esplori una stanza piena di giocattoli diversi e impari a conoscerli da solo. Il modello esamina i dati non etichettati, i modelli di apprendimento e le strutture senza ricevere le risposte "giuste".
L'apprendimento supervisionato utilizza dati che sono stati etichettati con input e output, a differenza dell'apprendimento non supervisionato, che non utilizza dati di output etichettati.
In poche parole, gli LLM sono formati principalmente utilizzando l'apprendimento supervisionato, ma possono anche utilizzare l'apprendimento non supervisionato per migliorare le loro capacità, ad esempio per l'analisi esplorativa e la riduzione della dimensionalità.
Qual è il volume di dati (in GB) necessario per addestrare un modello linguistico di grandi dimensioni?
Il mondo delle possibilità per il riconoscimento dei dati vocali e le applicazioni vocali è immenso e vengono utilizzate in diversi settori per una miriade di applicazioni.
L'addestramento di un modello linguistico di grandi dimensioni non è un processo valido per tutti, soprattutto quando si tratta dei dati necessari. Dipende da un sacco di cose:
- Il disegno del modello.
- Che lavoro deve fare?
- Il tipo di dati che stai utilizzando.
- Quanto bene vuoi che funzioni?
Detto questo, la formazione degli LLM di solito richiede un'enorme quantità di dati di testo. Ma di quanto massiccio stiamo parlando? Bene, pensa ben oltre i gigabyte (GB). Di solito guardiamo terabyte (TB) o addirittura petabyte (PB) di dati.
Considera GPT-3, uno dei più grandi LLM in circolazione. È addestrato 570 GB di dati di testo. Gli LLM più piccoli potrebbero aver bisogno di meno, forse 10-20 GB o anche 1 GB di gigabyte, ma è comunque molto.

Ma non si tratta solo della dimensione dei dati. Anche la qualità conta. I dati devono essere puliti e vari per aiutare il modello ad apprendere in modo efficace. E non puoi dimenticare altri pezzi chiave del puzzle, come la potenza di calcolo di cui hai bisogno, gli algoritmi che usi per l'addestramento e la configurazione hardware che hai. Tutti questi fattori giocano un ruolo importante nella formazione di un LLM.
L'ascesa dei modelli linguistici di grandi dimensioni: perché contano
Gli LLM non sono più solo un concetto o un esperimento. Stanno giocando sempre più un ruolo fondamentale nel nostro panorama digitale. Ma perché sta succedendo questo? Cosa rende questi LLM così importanti? Approfondiamo alcuni fattori chiave.
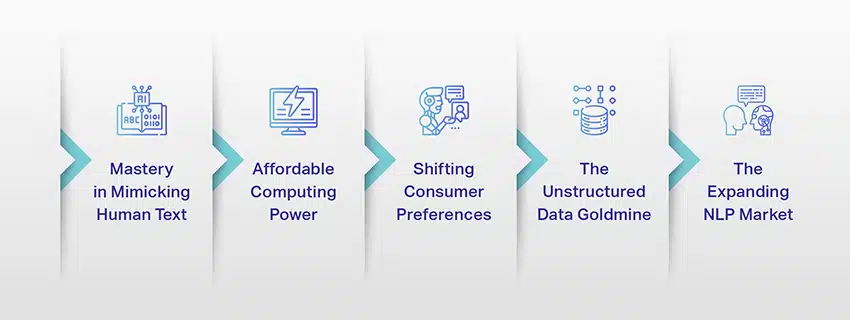
Padronanza nell'imitazione del testo umano
Gli LLM hanno trasformato il modo in cui gestiamo le attività basate sulla lingua. Costruiti utilizzando robusti algoritmi di apprendimento automatico, questi modelli sono dotati della capacità di comprendere le sfumature del linguaggio umano, inclusi il contesto, le emozioni e persino il sarcasmo, in una certa misura. Questa capacità di imitare il linguaggio umano non è una mera novità, ha implicazioni significative.
Le capacità avanzate di generazione di testo degli LLM possono migliorare tutto, dalla creazione di contenuti alle interazioni con il servizio clienti.
Immagina di poter porre una domanda complessa a un assistente digitale e ottenere una risposta che non solo abbia senso, ma sia anche coerente, pertinente e fornita in tono colloquiale. Questo è ciò che gli LLM stanno abilitando. Stanno alimentando un'interazione uomo-macchina più intuitiva e coinvolgente, arricchendo le esperienze degli utenti e democratizzando l'accesso alle informazioni.
Potenza di calcolo accessibile
L'ascesa di LLM non sarebbe stata possibile senza sviluppi paralleli nel campo dell'informatica. Più specificamente, la democratizzazione delle risorse computazionali ha svolto un ruolo significativo nell'evoluzione e nell'adozione degli LLM.
Le piattaforme basate su cloud offrono un accesso senza precedenti a risorse di elaborazione ad alte prestazioni. In questo modo, anche organizzazioni su piccola scala e ricercatori indipendenti possono addestrare sofisticati modelli di machine learning.
Inoltre, i miglioramenti nelle unità di elaborazione (come GPU e TPU), combinati con l'aumento del calcolo distribuito, hanno reso possibile l'addestramento di modelli con miliardi di parametri. Questa maggiore accessibilità della potenza di calcolo sta consentendo la crescita e il successo degli LLM, portando a più innovazione e applicazioni nel campo.
Spostare le preferenze dei consumatori
I consumatori oggi non vogliono solo risposte; vogliono interazioni coinvolgenti e riconoscibili. Man mano che sempre più persone crescono utilizzando la tecnologia digitale, è evidente che la necessità di una tecnologia che sembri più naturale e umana è in aumento. Gli LLM offrono un'opportunità senza pari per soddisfare queste aspettative. Generando testo simile a quello umano, questi modelli possono creare esperienze digitali coinvolgenti e dinamiche, che possono aumentare la soddisfazione e la lealtà degli utenti. Che si tratti di chatbot AI che forniscono assistenza clienti o assistenti vocali che forniscono aggiornamenti sulle notizie, gli LLM stanno inaugurando un'era di AI che ci comprende meglio.
La miniera d'oro dei dati non strutturati
I dati non strutturati, come le e-mail, i post sui social media e le recensioni dei clienti, sono un tesoro di approfondimenti. Si stima che sia finita 80% dei dati aziendali non è strutturato e cresce a un ritmo di 55% per anno. Questi dati sono una miniera d'oro per le aziende se sfruttati correttamente.
Gli LLM entrano in gioco qui, con la loro capacità di elaborare e dare un senso a tali dati su larga scala. Possono gestire attività come l'analisi del sentiment, la classificazione del testo, l'estrazione di informazioni e altro ancora, fornendo così preziose informazioni.
Che si tratti di identificare le tendenze dai post sui social media o di valutare il sentimento dei clienti dalle recensioni, gli LLM aiutano le aziende a navigare nella grande quantità di dati non strutturati e a prendere decisioni basate sui dati.
Il mercato della PNL in espansione
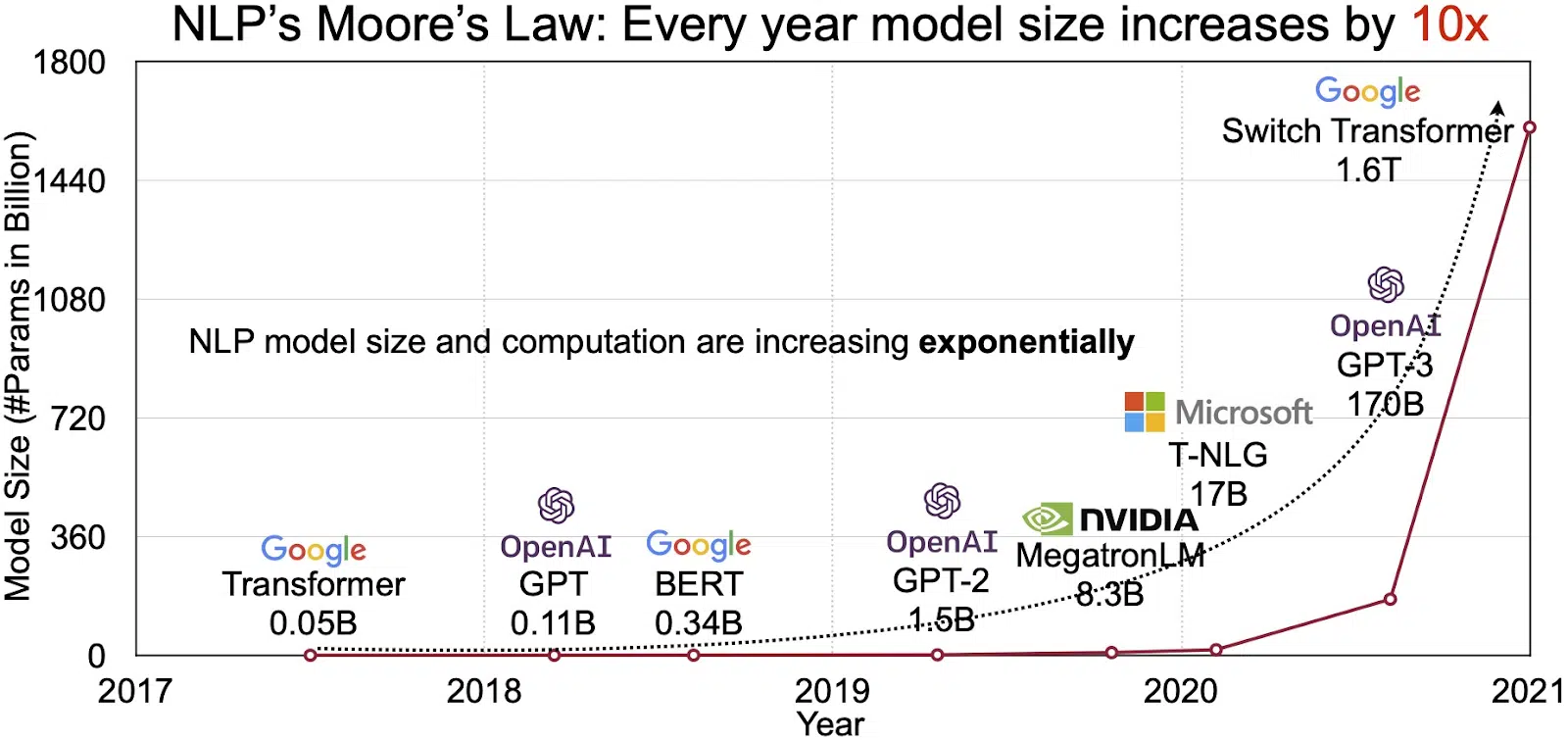
Il potenziale degli LLM si riflette nel mercato in rapida crescita dell'elaborazione del linguaggio naturale (NLP). Gli analisti prevedono che il mercato della PNL si espanderà $ 11 miliardi nel 2020 a oltre $ 35 miliardi entro il 2026. Ma non è solo la dimensione del mercato che si sta espandendo. Anche i modelli stessi stanno crescendo, sia nelle dimensioni fisiche che nel numero di parametri che gestiscono. L'evoluzione degli LLM nel corso degli anni, come si vede nella figura sottostante (fonte immagine: link), sottolinea la loro crescente complessità e capacità.
Casi d'uso popolari di modelli linguistici di grandi dimensioni
Ecco alcuni dei casi d'uso principali e più diffusi di LLM:
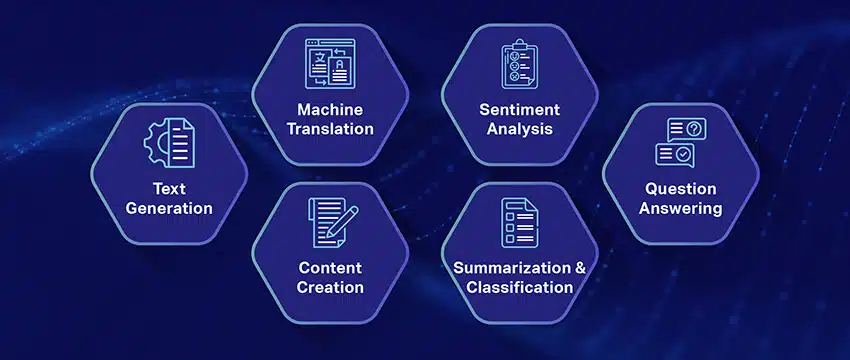
- Generazione di testo in linguaggio naturale: I Large Language Models (LLM) combinano la potenza dell'intelligenza artificiale e della linguistica computazionale per produrre autonomamente testi in linguaggio naturale. Possono soddisfare le diverse esigenze degli utenti come scrivere articoli, creare canzoni o impegnarsi in conversazioni con gli utenti.
- Traduzione tramite macchine: Gli LLM possono essere efficacemente impiegati per tradurre il testo tra qualsiasi coppia di lingue. Questi modelli sfruttano algoritmi di deep learning come le reti neurali ricorrenti per comprendere la struttura linguistica delle lingue di partenza e di arrivo, facilitando così la traduzione del testo di partenza nella lingua desiderata.
- Creazione di contenuti originali: Gli LLM hanno aperto strade alle macchine per generare contenuti coerenti e logici. Questo contenuto può essere utilizzato per creare post di blog, articoli e altri tipi di contenuto. I modelli attingono alla loro profonda esperienza di apprendimento profondo per formattare e strutturare il contenuto in un modo nuovo e intuitivo.
- Analisi dei sentimenti: Un'interessante applicazione dei Large Language Models è l'analisi del sentiment. In questo, il modello è addestrato a riconoscere e classificare stati emotivi e sentimenti presenti nel testo annotato. Il software può identificare emozioni come positività, negatività, neutralità e altri sentimenti complessi. Ciò può fornire preziose informazioni sul feedback dei clienti e opinioni su vari prodotti e servizi.
- Comprendere, riassumere e classificare il testo: Gli LLM stabiliscono una struttura praticabile per il software AI per interpretare il testo e il suo contesto. Istruendo il modello a comprendere e analizzare grandi quantità di dati, gli LLM consentono ai modelli di intelligenza artificiale di comprendere, riassumere e persino classificare il testo in diverse forme e modelli.
- Rispondendo alle domande: I Large Language Models dotano i sistemi di risposta alle domande (QA) della capacità di percepire e rispondere con precisione alla domanda in linguaggio naturale di un utente. Esempi popolari di questo caso d'uso includono ChatGPT e BERT, che esaminano il contesto di una query e setacciano una vasta raccolta di testi per fornire risposte pertinenti alle domande degli utenti.

Tagging parte del discorso (POS).
Le parole nelle frasi sono etichettate con la loro funzione grammaticale, come verbi, sostantivi, aggettivi, ecc. Questo processo aiuta il modello a comprendere la grammatica e i collegamenti tra le parole.

Riconoscimento entità designata (NER)
Le entità denominate come organizzazioni, luoghi e persone all'interno di una frase sono contrassegnate. Questo esercizio aiuta il modello a interpretare i significati semantici di parole e frasi e fornisce risposte più precise.

Analisi del sentimento
Ai dati di testo vengono assegnate etichette di sentimento come positivo, neutro o negativo, aiutando il modello a cogliere il sottofondo emotivo delle frasi. È particolarmente utile per rispondere a domande che coinvolgono emozioni e opinioni.
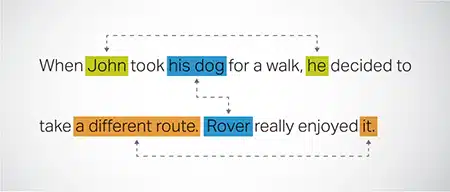
Risoluzione sulla coreferenza
Identificare e risolvere casi in cui la stessa entità è citata in parti diverse di un testo. Questo passaggio aiuta il modello a comprendere il contesto della frase, portando così a risposte coerenti.
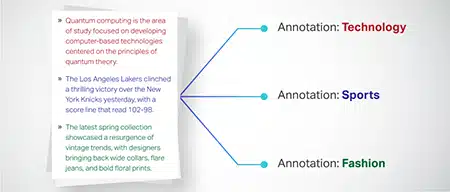
Classificazione del testo
I dati di testo sono classificati in gruppi predefiniti come recensioni di prodotti o articoli di notizie. Questo aiuta il modello a discernere il genere o l'argomento del testo, generando risposte più pertinenti.
L'offerta di Shaip
Saip offre una vasta gamma di servizi per aiutare le organizzazioni a gestire, analizzare e sfruttare al meglio i propri dati.
Scraping Web dei dati
Un servizio chiave offerto da Shaip è lo scraping dei dati. Ciò comporta l'estrazione di dati da URL specifici del dominio. Utilizzando strumenti e tecniche automatizzati, Shaip può raccogliere in modo rapido ed efficiente grandi volumi di dati da vari siti Web, manuali di prodotti, documentazione tecnica, forum online, recensioni online, dati del servizio clienti, documenti normativi del settore, ecc. Questo processo può essere prezioso per le aziende quando raccogliere dati pertinenti e specifici da una moltitudine di fonti.

Traduzione automatica
Sviluppa modelli utilizzando ampi set di dati multilingue abbinati a trascrizioni corrispondenti per tradurre il testo in varie lingue. Questo processo aiuta a smantellare gli ostacoli linguistici e promuove l'accessibilità delle informazioni.
Estrazione e creazione della tassonomia
Shaip può aiutare con l'estrazione e la creazione della tassonomia. Ciò comporta la classificazione e la categorizzazione dei dati in un formato strutturato che riflette le relazioni tra diversi punti dati. Ciò può essere particolarmente utile per le aziende nell'organizzazione dei propri dati, rendendoli più accessibili e più facili da analizzare. Ad esempio, in un'attività di e-commerce, i dati sui prodotti potrebbero essere classificati in base al tipo di prodotto, alla marca, al prezzo, ecc., rendendo più facile per i clienti navigare nel catalogo dei prodotti.
Raccolta Dati
I nostri servizi di raccolta dati forniscono dati critici del mondo reale o sintetici necessari per addestrare algoritmi di intelligenza artificiale generativa e migliorare l'accuratezza e l'efficacia dei tuoi modelli. I dati provengono da fonti imparziali, etiche e responsabili, tenendo presente la privacy e la sicurezza dei dati.

Domanda e risposta
La risposta alle domande (QA) è un sottocampo dell'elaborazione del linguaggio naturale incentrato sulla risposta automatica alle domande nel linguaggio umano. I sistemi di QA sono addestrati su testo e codice estesi, consentendo loro di gestire vari tipi di domande, comprese quelle fattuali, di definizione e basate sull'opinione. La conoscenza del dominio è fondamentale per lo sviluppo di modelli di QA su misura per campi specifici come l'assistenza clienti, l'assistenza sanitaria o la catena di fornitura. Tuttavia, gli approcci generativi di QA consentono ai modelli di generare testo senza la conoscenza del dominio, basandosi esclusivamente sul contesto.
Il nostro team di specialisti può studiare meticolosamente documenti o manuali completi per generare coppie Domanda-Risposta, facilitando la creazione di AI generativa per le aziende. Questo approccio può affrontare efficacemente le richieste degli utenti estraendo informazioni pertinenti da un vasto corpus. I nostri esperti certificati garantiscono la produzione di coppie di domande e risposte di alta qualità che abbracciano diversi argomenti e domini.

Riepilogo del testo
I nostri specialisti sono in grado di distillare conversazioni complete o lunghi dialoghi, fornendo riassunti succinti e approfonditi da dati di testo estesi.

Generazione di testo
Addestra i modelli utilizzando un ampio set di dati di testo in stili diversi, come articoli di notizie, narrativa e poesia. Questi modelli possono quindi generare vari tipi di contenuto, tra cui notizie, voci di blog o post sui social media, offrendo una soluzione economica e che fa risparmiare tempo per la creazione di contenuti.
Riconoscimento vocale
Sviluppare modelli in grado di comprendere il linguaggio parlato per varie applicazioni. Ciò include assistenti ad attivazione vocale, software di dettatura e strumenti di traduzione in tempo reale. Il processo prevede l'utilizzo di un set di dati completo composto da registrazioni audio della lingua parlata, abbinate alle trascrizioni corrispondenti.

Consigli sul prodotto
Sviluppa modelli utilizzando set di dati estesi di cronologie di acquisto dei clienti, incluse etichette che indicano i prodotti che i clienti sono inclini ad acquistare. L'obiettivo è quello di fornire suggerimenti precisi ai clienti, aumentando così le vendite e aumentando la soddisfazione del cliente.
Sottotitoli delle immagini
Rivoluziona il tuo processo di interpretazione delle immagini con il nostro servizio di sottotitoli delle immagini all'avanguardia basato sull'intelligenza artificiale. Infondiamo vitalità nelle immagini producendo descrizioni accurate e contestualmente significative. Questo apre la strada a possibilità innovative di coinvolgimento e interazione con i tuoi contenuti visivi per il tuo pubblico.

Formazione sui servizi di sintesi vocale
Forniamo un ampio set di dati composto da registrazioni audio del parlato umano, ideale per l'addestramento di modelli di intelligenza artificiale. Questi modelli sono in grado di generare voci naturali e coinvolgenti per le tue applicazioni, offrendo così un'esperienza sonora distintiva e coinvolgente per i tuoi utenti.



