



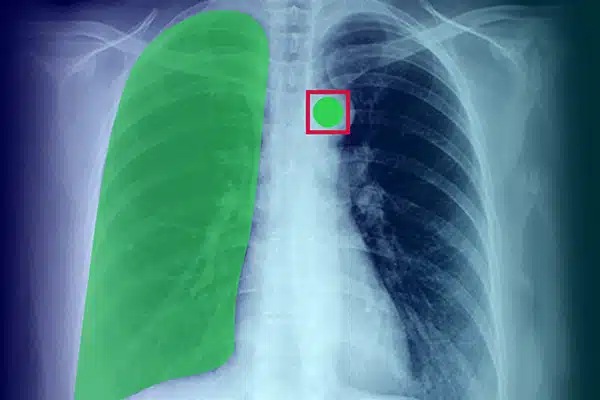
Annotazione di immagine
Migliora l'intelligenza artificiale medica annotando i dati visivi provenienti da raggi X, scansioni TC e risonanza magnetica. Garantire che i modelli di intelligenza artificiale funzionino in modo eccellente nella diagnostica e nel trattamento, guidati dall'etichettatura dei dati esperta. Ottieni risultati migliori per i pazienti con informazioni di imaging superiori.
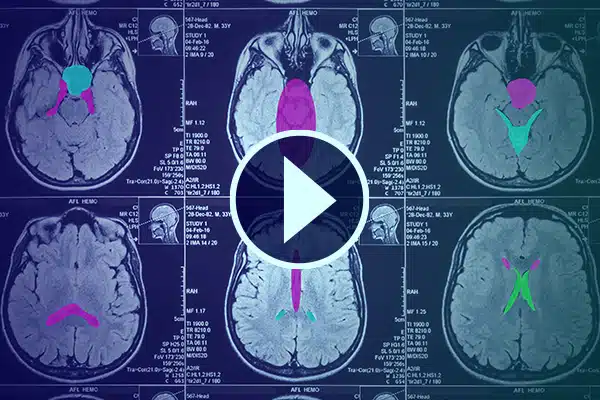
Annotazione video
Avanza l'intelligenza artificiale nel settore sanitario con annotazioni video dettagliate. Migliora l'apprendimento dell'intelligenza artificiale con classificazioni e segmentazioni nei filmati medici. Migliora l'intelligenza artificiale chirurgica e il monitoraggio dei pazienti per migliorare l'erogazione dell'assistenza sanitaria e la diagnostica.
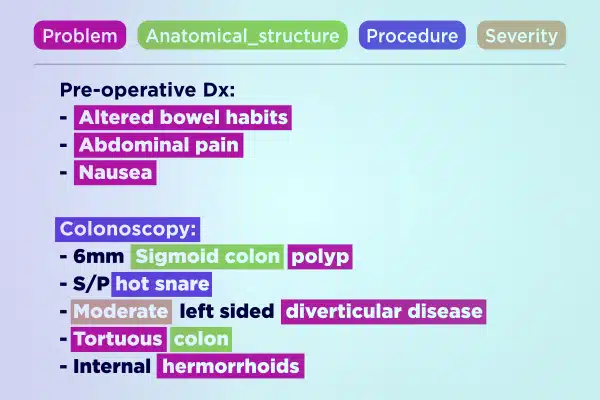
Annotazione di testo
Semplifica lo sviluppo dell'intelligenza artificiale medica con dati di testo annotati da esperti. Analizza e arricchisci rapidamente vasti volumi di testo, dalle note scritte a mano ai rapporti assicurativi. Garantisci insight accurati e utilizzabili per i progressi nel settore sanitario.

Annotazione audio
Sfrutta l'esperienza della PNL per annotare ed etichettare i dati audio medici in modo accurato. Realizza sistemi ad assistenza vocale per operazioni cliniche senza interruzioni e integra l'intelligenza artificiale in vari prodotti sanitari ad attivazione vocale. Migliora la precisione diagnostica con la cura dei dati audio da parte di esperti.

Codifica medica
Semplifica la documentazione medica convertendola in codici universali con la codifica medica AI. Garantisci la precisione, migliora l'efficienza della fatturazione e supporta l'erogazione di servizi sanitari senza soluzione di continuità con l'assistenza IA all'avanguardia nella codifica delle cartelle cliniche.

Fase 1: Competenza nel dominio tecnico (comprendere l'ambito e le linee guida per le annotazioni)

Fase 2: Formazione di risorse appropriate per il progetto

Fase 3: Ciclo di feedback e QA dei documenti annotati
Radiologia
Il nostro servizio di annotazione delle immagini radiologiche migliora la diagnostica dell'intelligenza artificiale e include un ulteriore livello di competenza. Ogni scansione a raggi X, MRI e TC è meticolosamente etichettata e rivista da un esperto in materia. Questo passaggio aggiuntivo nella formazione e nella revisione aumenta la capacità dell'IA di individuare anomalie e malattie. Migliora la precisione prima della consegna ai nostri clienti.

Cardiologia
La nostra annotazione di immagini incentrata sulla cardiologia migliora la diagnostica dell'intelligenza artificiale. Coinvolgiamo esperti di cardiologia che etichettano immagini complesse relative al cuore e addestrano i nostri modelli di intelligenza artificiale. Prima di inviare i dati ai clienti, questi specialisti esaminano ogni immagine per garantire la massima precisione. Questo processo consente all’intelligenza artificiale di rilevare le condizioni cardiache in modo più preciso.
Odontoiatria
Il nostro servizio di annotazione delle immagini in odontoiatria etichetta le immagini dentali per migliorare gli strumenti diagnostici dell'intelligenza artificiale. Identificando accuratamente carie, problemi di allineamento e altre condizioni dentali, le nostre PMI consentono all’intelligenza artificiale di migliorare i risultati dei pazienti e supportare i dentisti nella pianificazione precisa del trattamento e nella diagnosi precoce.


















Persone
Team dedicati e formati:
- Oltre 30,000 collaboratori per la creazione di dati, l'etichettatura e il controllo qualità
- Team di gestione del progetto con credenziali
- Team di sviluppo prodotto esperto
- Talent Pool Sourcing & Onboarding Team

Processo
La massima efficienza del processo è assicurata da:
- Robusto processo Stage-Gate 6 Sigma
- Un team dedicato di cinture nere 6 Sigma: titolari di processi chiave e conformità alla qualità
- Miglioramento continuo e ciclo di feedback

Piattaforma
La piattaforma brevettata offre vantaggi:
- Piattaforma end-to-end basata sul web
- Qualità impeccabile
- TAT . più veloce
- Consegna senza soluzione di continuità



