Se usi Siri, Alexa, Cortana, Amazon Echo o altri come parte della tua vita quotidiana, lo accetteresti Il riconoscimento vocale è diventata una parte onnipresente della nostra vita. Queste basato sull'intelligenza artificiale gli assistenti vocali convertono le domande verbali degli utenti in testo, interpretano e comprendono ciò che l'utente sta dicendo per trovare una risposta adeguata.
È necessaria una raccolta di dati di qualità per sviluppare modelli di riconoscimento vocale e affidabili. Ma, in via di sviluppo software di riconoscimento vocale non è un compito semplice, proprio perché trascrivere il discorso umano in tutta la sua complessità, come il ritmo, l'accento, il tono e la chiarezza, è difficile. E, quando aggiungi emozioni a questo mix complesso, diventa una sfida.
Che cos'è il riconoscimento vocale?
Il riconoscimento vocale è la capacità del software di riconoscere ed elaborare discorso umano nel testo. Sebbene la differenza tra riconoscimento vocale e riconoscimento vocale possa sembrare soggettiva a molti, ci sono alcune differenze fondamentali tra i due.
Sebbene sia il riconoscimento vocale che quello vocale facciano parte della tecnologia dell'assistente vocale, svolgono due diverse funzioni. Il riconoscimento vocale esegue trascrizioni automatiche del parlato umano e dei comandi in testo, mentre il riconoscimento vocale si occupa solo del riconoscimento della voce di chi parla.
Tipi di riconoscimento vocale
Prima di buttarci dentro tipi di riconoscimento vocale, diamo una breve occhiata ai dati di riconoscimento vocale.
I dati di riconoscimento vocale sono una raccolta di registrazioni audio vocali umane e trascrizioni di testo che aiutano ad addestrare i sistemi di apprendimento automatico riconoscimento vocale.
Le registrazioni audio e le trascrizioni vengono inserite nel sistema ML in modo che l'algoritmo possa essere addestrato a riconoscere le sfumature del parlato e a comprenderne il significato.
Sebbene ci siano molti posti in cui è possibile ottenere set di dati preconfezionati gratuiti, è meglio ottenerli set di dati personalizzati per i tuoi progetti È possibile selezionare la dimensione della raccolta, i requisiti audio e degli altoparlanti e la lingua disponendo di un set di dati personalizzato.
Spettro dei dati vocali
Dati vocali lo spettro identifica la qualità e il tono del parlato che vanno da naturale a innaturale.
Dati di riconoscimento vocale con script
Come suggerisce il nome, il discorso con script è una forma controllata di dati. Gli oratori registrano frasi specifiche da un testo preparato. Questi sono in genere utilizzati per fornire comandi, sottolineando come il parola o frase viene detto piuttosto che ciò che viene detto.
Il riconoscimento vocale con script può essere utilizzato durante lo sviluppo di un assistente vocale che dovrebbe raccogliere i comandi emessi utilizzando vari accenti degli altoparlanti.
Riconoscimento vocale basato sullo scenario
In un discorso basato su uno scenario, all'oratore viene chiesto di immaginare uno scenario particolare ed emettere a comando vocale in base allo scenario. In questo modo, il risultato è una raccolta di comandi vocali che non sono programmati ma controllati.
I dati vocali basati su scenari sono richiesti dagli sviluppatori che desiderano sviluppare un dispositivo in grado di comprendere il parlato quotidiano con le sue varie sfumature. Ad esempio, chiedendo indicazioni per andare al Pizza Hut più vicino utilizzando una serie di domande.
Riconoscimento vocale naturale
Proprio alla fine dello spettro del discorso c'è un discorso spontaneo, naturale e non controllato in alcun modo. L'oratore parla liberamente usando il suo tono di conversazione naturale, lingua, tono e tenore.
Se desideri addestrare un'applicazione basata su ML sul riconoscimento vocale multi-altoparlante, allora un'applicazione senza script o discorso colloquiale set di dati è utile.
Componenti di raccolta dati per progetti vocali
 Una serie di passaggi coinvolti nella raccolta dei dati vocali assicurano che i dati raccolti siano di qualità e aiutano nella formazione di modelli basati sull'IA di alta qualità.
Una serie di passaggi coinvolti nella raccolta dei dati vocali assicurano che i dati raccolti siano di qualità e aiutano nella formazione di modelli basati sull'IA di alta qualità.
Comprendere le risposte degli utenti richieste
Inizia comprendendo le risposte utente richieste per il modello. Per sviluppare un modello di riconoscimento vocale, dovresti raccogliere dati che rappresentino da vicino il contenuto di cui hai bisogno. Raccogli i dati dalle interazioni del mondo reale per comprendere le interazioni e le risposte degli utenti. Se stai creando un assistente di chat basato sull'intelligenza artificiale, guarda i registri delle chat, le registrazioni delle chiamate, le risposte della finestra di dialogo della chat per creare un set di dati.
Scruta il linguaggio specifico del dominio
Per un set di dati di riconoscimento vocale sono necessari contenuti sia generici che specifici del dominio. Dopo aver raccolto i dati vocali generici, è necessario passare al setaccio i dati e separare il generico dallo specifico.
Ad esempio, i clienti possono chiamare per chiedere un appuntamento per controllare il glaucoma in un centro oculistico. Chiedere un appuntamento è un termine molto generico, ma il glaucoma è specifico del dominio.
Inoltre, durante l'addestramento di un modello ML di riconoscimento vocale, assicurati di addestrarlo a identificare le frasi anziché individualmente parole riconosciute.
Registra il discorso umano
Dopo aver raccolto i dati dai due passaggi precedenti, il passaggio successivo comporterebbe che gli esseri umani registrino le affermazioni raccolte.
È essenziale mantenere una lunghezza ideale della sceneggiatura. Chiedere alle persone di leggere più di 15 minuti di testo potrebbe essere controproducente. Mantieni un intervallo minimo di 2-3 secondi tra ogni affermazione registrata.
Consenti alla registrazione di essere dinamica
Crea un archivio vocale di varie persone, accenti parlati, stili registrati in diverse circostanze, dispositivi e ambienti. Se la maggior parte degli utenti futuri utilizzerà la rete fissa, il database della tua raccolta vocale dovrebbe avere una rappresentazione significativa che soddisfi tale requisito.

Indurre variabilità nella registrazione vocale
Una volta che l'ambiente di destinazione è stato impostato, chiedi ai tuoi soggetti di raccolta dati di leggere lo script preparato in un ambiente simile. Chiedi ai soggetti di non preoccuparsi degli errori e di mantenere la resa il più naturale possibile. L'idea è di avere un grande gruppo di persone che registrano la sceneggiatura nello stesso ambiente.
Trascrivi i discorsi
Dopo aver registrato lo script utilizzando più soggetti (con errori), dovresti procedere con la trascrizione. Mantieni intatti gli errori, in quanto ciò ti aiuterebbe a ottenere dinamismo e varietà nei dati raccolti.
Invece di fare in modo che gli esseri umani trascrivano l'intero testo parola per parola, puoi coinvolgere un motore di sintesi vocale per eseguire la trascrizione. Tuttavia, ti suggeriamo anche di utilizzare trascrittori umani per correggere gli errori.
Sviluppa un set di prova
Lo sviluppo di un set di test è fondamentale in quanto è in testa alla classifica modello linguistico.
Crea un paio del discorso e del testo corrispondente e trasformali in segmenti.
Dopo aver raccolto gli elementi raccolti, estrarre un campionamento del 20%, che costituisce il test set. Non è il set di addestramento, ma questi dati estratti ti faranno sapere se il modello addestrato trascrive l'audio su cui non è stato addestrato.
Costruisci un modello di formazione linguistica e misura
Ora costruisci il modello del linguaggio di riconoscimento vocale utilizzando le istruzioni specifiche del dominio e, se necessario, ulteriori variazioni. Dopo aver addestrato il modello, dovresti iniziare a misurarlo.
Prendi il modello di addestramento (con l'80% di segmenti audio selezionati) e testalo rispetto al set di test (set di dati estratti per il 20%) per verificare la presenza di previsioni e affidabilità. Verifica la presenza di errori, schemi e concentrati sui fattori ambientali che possono essere corretti.
Possibili casi d'uso o applicazioni
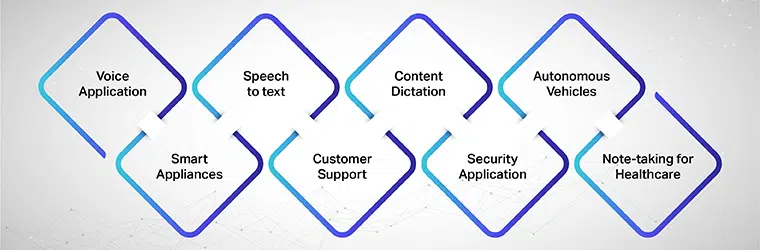
Applicazione vocale, elettrodomestici intelligenti, sintesi vocale, assistenza clienti, dettatura dei contenuti, applicazione di sicurezza, veicoli autonomi, presa di appunti per l'assistenza sanitaria.
Il riconoscimento vocale apre un mondo di possibilità e l'adozione da parte degli utenti delle applicazioni vocali è aumentata nel corso degli anni.
Alcune delle applicazioni comuni di tecnologia di riconoscimento vocale includono:
Applicazione di ricerca vocale
Secondo Google, su 20% delle ricerche effettuate sull'app Google sono vocali. Otto miliardi di persone si prevede di utilizzare gli assistenti vocali entro il 2023, un forte aumento rispetto ai 6.4 miliardi previsti nel 2022.
L'adozione della ricerca vocale è aumentata in modo significativo nel corso degli anni e si prevede che questa tendenza continuerà. I consumatori si affidano alla ricerca vocale per cercare query, acquistare prodotti, individuare attività commerciali, trovare attività commerciali locali e altro ancora.
Dispositivi domestici/elettrodomestici intelligenti
La tecnologia di riconoscimento vocale viene utilizzata per fornire comandi vocali a dispositivi intelligenti domestici come TV, luci e altri elettrodomestici. 66% di consumatori nel Regno Unito, negli Stati Uniti e in Germania hanno dichiarato di utilizzare assistenti vocali quando utilizzano dispositivi e altoparlanti intelligenti.
Discorso al testo
Le applicazioni di sintesi vocale vengono utilizzate per facilitare l'elaborazione gratuita durante la digitazione di e-mail, documenti, rapporti e altro. Discorso al testo elimina il tempo necessario per digitare documenti, scrivere libri e e-mail, sottotitolare video e tradurre testo.
Assistenza clienti
Le applicazioni di riconoscimento vocale vengono utilizzate principalmente nel servizio clienti e nell'assistenza. Un sistema di riconoscimento vocale aiuta a fornire soluzioni di servizio clienti 24 ore su 7, XNUMX giorni su XNUMX a un costo accessibile con un numero limitato di rappresentanti.
Dettatura dei contenuti
La dettatura dei contenuti è un'altra caso d'uso del riconoscimento vocale che aiuta studenti e accademici a scrivere contenuti estesi in una frazione di tempo. È piuttosto utile per gli studenti svantaggiati a causa di cecità o problemi di vista.
Applicazione di sicurezza
Il riconoscimento vocale è ampiamente utilizzato per scopi di sicurezza e autenticazione identificando caratteristiche vocali uniche. Invece di fare in modo che la persona si identifichi utilizzando informazioni personali rubate o utilizzate in modo improprio, la biometria vocale aumenta la sicurezza.
Inoltre, il riconoscimento vocale per motivi di sicurezza ha migliorato i livelli di soddisfazione dei clienti in quanto elimina il processo di accesso esteso e la duplicazione delle credenziali.
Comandi vocali per veicoli
I veicoli, principalmente le automobili, ora hanno una funzione di riconoscimento vocale comune per migliorare la sicurezza di guida. Aiuta i conducenti a concentrarsi sulla guida accettando semplici comandi vocali come selezionare stazioni radio, effettuare chiamate o ridurre il volume.
Prendere appunti per l'assistenza sanitaria
Il software di trascrizione medica creato utilizzando algoritmi di riconoscimento vocale acquisisce facilmente note vocali, comandi, diagnosi e sintomi dei medici. Prendere appunti medici aumenta la qualità e l'urgenza nel settore sanitario.
Hai in mente un progetto di riconoscimento vocale che può trasformare la tua attività? Tutto ciò di cui potresti aver bisogno è un set di dati di riconoscimento vocale personalizzato.
Un software di riconoscimento vocale basato sull'intelligenza artificiale deve essere addestrato su set di dati affidabili su algoritmi di apprendimento automatico per integrare sintassi, grammatica, struttura delle frasi, emozioni e sfumature del linguaggio umano. Ancora più importante, il software dovrebbe imparare e rispondere continuamente, crescendo ad ogni interazione.
In Shaip, forniamo set di dati di riconoscimento vocale completamente personalizzati per vari progetti di machine learning. Con Shaip, hai accesso a dati di formazione su misura di altissima qualità che può essere utilizzato per costruire e commercializzare un sistema di riconoscimento vocale affidabile. Mettiti in contatto con i nostri esperti per una comprensione completa delle nostre offerte.
[Leggi anche: La guida completa all'IA conversazionale]