
Internet ha aperto le porte alle persone che esprimono liberamente opinioni, opinioni e suggerimenti su qualsiasi cosa nel mondo Social Media, siti Web e blog. Oltre a esprimere le proprie opinioni, le persone (clienti) influenzano anche le decisioni di acquisto degli altri. Il sentimento, negativo o positivo, è fondamentale per qualsiasi azienda o marchio preoccupato per la vendita dei propri prodotti o servizi.
Aiutare le aziende a estrarre i commenti per uso aziendale lo è Elaborazione del linguaggio naturale. Un'impresa su quattro ha in programma di implementare la tecnologia NLP entro il prossimo anno per potenziare le proprie decisioni aziendali. Utilizzando la sentiment analysis, la NLP aiuta le aziende a ricavare informazioni interpretabili da dati grezzi e non strutturati.
Opinione mineraria o sentiment analysis è una tecnica di PNL utilizzata per identificare il sentimento esatto – positivo, negativo o neutro – associato a commenti e feedback. Con l'aiuto della PNL, le parole chiave nei commenti vengono analizzate per determinare le parole positive o negative contenute nella parola chiave.
I sentimenti vengono valutati su un sistema di ridimensionamento che assegna i punteggi dei sentimenti alle emozioni in un pezzo di testo (determinando il testo come positivo o negativo).
Che cos'è l'analisi del sentimento multilingue?

Come suggerisce il nome, analisi del sentimento multilingue è la tecnica per eseguire i punteggi del sentiment per più di una lingua. Tuttavia, non è così semplice. La nostra cultura, lingua ed esperienze influenzano notevolmente il nostro comportamento di acquisto e le nostre emozioni. Senza una buona comprensione della lingua, del contesto e della cultura dell'utente, è impossibile comprendere con precisione le intenzioni, le emozioni e le interpretazioni dell'utente.
Sebbene l'automazione sia la risposta a molti dei nostri problemi odierni, traduzione automatica il software non sarà in grado di cogliere le sfumature del linguaggio, i colloquialismi, le sottigliezze e i riferimenti culturali nei commenti e recensioni sta traducendo. Lo strumento ML potrebbe fornirti una traduzione, ma potrebbe non essere utile. Questo è il motivo per cui è necessaria l'analisi del sentiment multilingue.
Perché è necessaria l'analisi del sentimento multilingue?
La maggior parte delle aziende utilizza l'inglese come mezzo di comunicazione, ma non è utilizzato dalla maggior parte dei consumatori in tutto il mondo.
Secondo Ethnologue, circa il 13% della popolazione mondiale parla inglese. Inoltre, il British Council afferma che circa il 25% della popolazione mondiale ha una discreta conoscenza dell'inglese. Se si deve credere a questi numeri, gran parte dei consumatori interagisce tra loro e con l'azienda in una lingua diversa dall'inglese.
Se l'obiettivo principale delle aziende è mantenere intatta la propria base clienti e attrarre nuovi clienti, devono comprendere intimamente le opinioni dei loro clienti espresse nei loro lingua nativa. Rivedere manualmente ogni commento o tradurli in inglese è un processo ingombrante che non produrrà risultati efficaci.
Una soluzione sostenibile è sviluppare il multilinguismo sistemi di analisi del sentimento che rilevano e analizzano le opinioni, le emozioni e i suggerimenti dei clienti nei social media, nei forum, nei sondaggi e altro ancora.
Passaggi per eseguire l'analisi del sentimento multilingue
Analisi del sentimento, indipendentemente dal fatto che sia in un'unica lingua o diverse lingue, è un processo che richiede l'applicazione di modelli di apprendimento automatico, elaborazione del linguaggio naturale e tecniche di analisi dei dati per l'estrazione punteggio del sentimento multilingue dai dati.
I passaggi coinvolti nell'analisi del sentimento multilingue sono
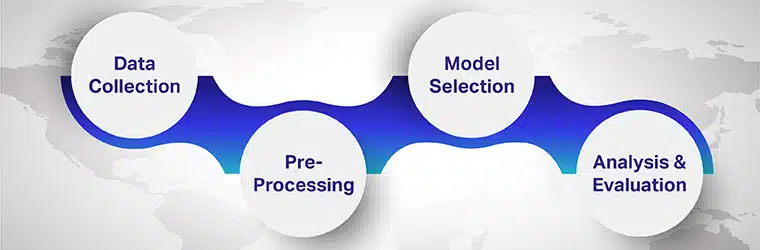
Passaggio 1: raccolta dei dati
La raccolta dei dati è il primo passo nell'applicazione dell'analisi del sentimento. Per creare un multilingue modello di analisi del sentimento, è importante acquisire dati in una varietà di lingue. Tutto dipenderà dalla qualità dei dati raccolti, annotati ed etichettati. Puoi trarre dati da API, repository open source e publisher.
Passaggio 2: pre-elaborazione
I dati web raccolti dovrebbero essere puliti e le informazioni raccolte da essi. Le parti del testo che non trasmettono un significato particolare, come "l'"è" e altro, dovrebbero essere rimosse. Inoltre, il testo dovrebbe essere raggruppato in gruppi di parole da classificare per trasmettere un significato positivo o negativo.
Per migliorare la qualità della classificazione, il contenuto deve essere ripulito da rumori, come tag HTML, pubblicità e script. La lingua, il lessico e la grammatica utilizzati dalle persone sono diversi a seconda del social network. È importante normalizzare tale contenuto e prepararlo per la pre-elaborazione.
Un altro passaggio fondamentale nella pre-elaborazione consiste nell'utilizzare l'elaborazione del linguaggio naturale per dividere le frasi, rimuovere le parole di arresto, taggare parti del discorso, trasformare le parole nella loro forma radice e tokenizzare le parole in simboli e testo.
Passaggio 3: selezione del modello
Modello basato su regole: Il metodo più semplice di analisi semantica multilingue è basato su regole. L'algoritmo basato su regole esegue l'analisi sulla base di un insieme di regole predeterminate programmate dagli esperti.
La regola potrebbe specificare parole o frasi positive o negative. Se prendi una recensione su un prodotto o un servizio, ad esempio, potrebbe contenere parole positive o negative come "ottimo", "lento", "attendere" e "utile". Questo metodo semplifica la classificazione delle parole, ma potrebbe classificare erroneamente parole complicate o meno frequenti.
Modello automatico: Il modello automatico esegue l'analisi del sentiment multilingue senza il coinvolgimento di moderatori umani. Sebbene il modello di apprendimento automatico sia costruito utilizzando lo sforzo umano, può funzionare automaticamente per fornire risultati accurati una volta sviluppato.
I dati del test vengono analizzati e ogni commento viene etichettato manualmente come positivo o negativo. Il modello ML imparerà quindi dai dati del test confrontando il nuovo testo con i commenti esistenti e classificandoli.
Passaggio 4: analisi e valutazione
I modelli basati su regole e di apprendimento automatico possono essere migliorati e migliorati nel tempo e nell'esperienza. Un lessico di parole usate meno frequentemente o risultati in tempo reale per sentimenti multilingue può essere aggiornato per una classificazione più rapida e accurata.
La sfida della traduzione
Non basta la traduzione? In realtà, no!
La traduzione implica il trasferimento di testo o gruppi di testo da una lingua e la ricerca di un equivalente in un'altra. Tuttavia, la traduzione non è né semplice né efficace.
Questo perché gli esseri umani usano il linguaggio non solo per comunicare i propri bisogni ma anche per esprimere le proprie emozioni. Inoltre, ci sono forti differenze tra le diverse lingue, come inglese, hindi, mandarino e tailandese. Aggiungi a questo mix letterario l'uso di emozioni, slang, modi di dire, sarcasmo ed emoji. Non è possibile ottenere una traduzione accurata del testo.
Alcune delle principali sfide di traduzione automatica sono
- Soggettività
- Contesto
- Slang e modi di dire
- Sarcasmo
- Confronti
- Neutralità
- Emoji e uso moderno delle parole.
Senza comprendere accuratamente il significato previsto delle recensioni, dei commenti e delle comunicazioni riguardanti i loro prodotti, prezzi, servizi, caratteristiche e qualità, le aziende non saranno in grado di comprendere le esigenze e le opinioni dei clienti.
L'analisi del sentimento multilingue è un processo impegnativo. Ogni lingua ha il suo lessico, sintassi, morfologia e fonologia unici. Aggiungi a questo la cultura, lo slang, sentimenti espressi, sarcasmo e tonalità, e hai un puzzle impegnativo che richiede una soluzione ML efficiente basata sull'intelligenza artificiale.
È necessario un set di dati multilingue completo per sviluppare un robusto multilinguismo strumenti di analisi del sentiment in grado di elaborare recensioni e fornire approfondimenti potenti alle aziende. Shaip è il leader di mercato nella fornitura di set di dati personalizzati, etichettati e annotati in diverse lingue che aiutano a sviluppare in modo efficiente e accurato soluzioni di analisi del sentimento multilingue.


