
L'intelligenza artificiale favorisce interazioni simili a quelle umane con i sistemi informatici, mentre l'apprendimento automatico consente a queste macchine di imparare a imitare l'intelligenza umana attraverso ogni interazione. Ma cosa alimenta questi strumenti ML e AI altamente avanzati? Annotazione dei dati.
I dati sono la materia prima che alimenta gli algoritmi ML: più dati utilizzi, migliore sarà il prodotto AI. Sebbene sia di fondamentale importanza avere accesso a grandi quantità di dati, è altrettanto importante assicurarsi che siano accuratamente annotati per produrre risultati fattibili. L'annotazione dei dati è la potenza dei dati alla base di prestazioni algoritmiche ML avanzate, affidabili e accurate.
Ruolo dell'annotazione dei dati nell'addestramento AI
L'annotazione dei dati svolge un ruolo chiave nella formazione ML e nel successo complessivo dei progetti di intelligenza artificiale. Aiuta a identificare immagini, dati, obiettivi e video specifici e li etichetta per facilitare alla macchina l'identificazione di modelli e la classificazione dei dati. È un'attività guidata dall'uomo che addestra il modello ML a fare previsioni accurate.
Se l'annotazione dei dati non viene eseguita in modo accurato, l'algoritmo ML non può associare facilmente gli attributi agli oggetti.
Importanza dei dati di addestramento annotati per i sistemi di intelligenza artificiale
L'annotazione dei dati consente il funzionamento accurato dei modelli ML. Esiste un legame indiscutibile tra l'accuratezza e la precisione dell'annotazione dei dati e il successo del progetto AI.
Si prevede che il valore del mercato globale dell'IA, stimato in 119 miliardi di dollari nel 2022, raggiungerà $ 1,597 miliardi entro 2030, in crescita a un CAGR del 38% durante il periodo. Mentre l'intero progetto AI passa attraverso diversi passaggi critici, la fase di annotazione dei dati è dove il tuo progetto si trova nella fase più significativa.
La raccolta di dati per il bene dei dati non aiuterà molto il tuo progetto. Hai bisogno di enormi quantità di dati pertinenti e di alta qualità per implementare con successo il tuo progetto di intelligenza artificiale. Circa l'80% del tuo tempo nello sviluppo di progetti ML viene dedicato ad attività relative ai dati, come l'etichettatura, lo scrubbing, l'aggregazione, l'identificazione, l'aumento e l'annotazione.
L'annotazione dei dati è un'area in cui gli esseri umani hanno un vantaggio rispetto ai computer perché abbiamo la capacità innata di decifrare l'intento, superare l'ambiguità e classificare le informazioni incerte.
Perché l'annotazione dei dati è importante?
Il valore e la credibilità della tua soluzione di intelligenza artificiale dipendono in gran parte dalla qualità dell'input dei dati utilizzato per l'addestramento del modello.
Una macchina non può elaborare le immagini come facciamo noi; hanno bisogno di essere addestrati a riconoscere i modelli attraverso la formazione. Poiché i modelli di machine learning soddisfano un'ampia gamma di applicazioni - soluzioni critiche come l'assistenza sanitaria e i veicoli autonomi - in cui qualsiasi errore nell'annotazione dei dati può avere ripercussioni pericolose.
L'annotazione dei dati garantisce che la tua soluzione AI funzioni al massimo delle sue capacità. L'addestramento di un modello ML per interpretare accuratamente il suo ambiente attraverso modelli e correlazioni, fare previsioni e intraprendere le azioni necessarie richiede un'elevata categorizzazione e annotazione dati di allenamento. L'annotazione mostra al modello ML la previsione richiesta contrassegnando, trascrivendo ed etichettando le caratteristiche critiche nel set di dati.
Apprendimento supervisionato
Prima di approfondire l'annotazione dei dati, sveliamo l'annotazione dei dati attraverso l'apprendimento supervisionato e non supervisionato.
Una sottocategoria di apprendimento automatico supervisionato dall'apprendimento automatico indica l'addestramento del modello di intelligenza artificiale con l'aiuto di un set di dati ben etichettato. In un metodo di apprendimento supervisionato, alcuni dati sono già accuratamente etichettati e annotati. Il modello ML, se esposto a nuovi dati, utilizza i dati di addestramento per elaborare una previsione accurata basata sui dati etichettati.
Ad esempio, il modello ML viene addestrato su un armadio pieno di diversi tipi di vestiti. Il primo passo nella formazione sarebbe addestrare il modello con diversi tipi di vestiti utilizzando le caratteristiche e gli attributi di ogni capo di stoffa. Dopo la formazione, la macchina sarà in grado di identificare capi di abbigliamento separati applicando le sue precedenti conoscenze o formazione. L'apprendimento supervisionato può essere classificato in classificazione (basata sulla categoria) e regressione (basata sul valore reale).
In che modo l'annotazione dei dati influisce sulle prestazioni dei sistemi di intelligenza artificiale
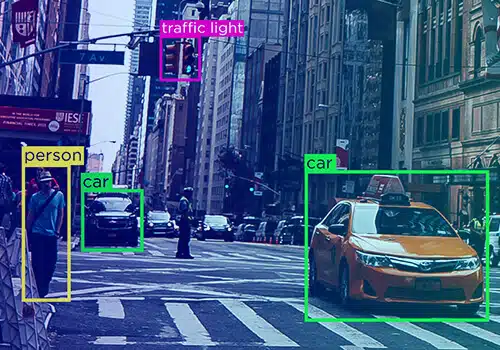 I dati non sono mai una singola entità: assumono forme diverse: testo, video e immagine. Inutile dire che l'annotazione dei dati è disponibile in diverse forme.
I dati non sono mai una singola entità: assumono forme diverse: testo, video e immagine. Inutile dire che l'annotazione dei dati è disponibile in diverse forme.
Affinché la macchina comprenda e identifichi con precisione le diverse entità, è importante sottolineare la qualità del Named Entity Tagging. Un errore nell'etichettatura e nell'annotazione e il ML non è riuscito a distinguere tra Amazon: il negozio di e-commerce, il fiume o un pappagallo.
Inoltre, l'annotazione dei dati aiuta le macchine a riconoscere l'intento sottile, una qualità che è naturale per gli esseri umani. Comunichiamo in modo diverso e gli esseri umani comprendono sia i pensieri espressi esplicitamente che i messaggi impliciti. Ad esempio, le risposte o le recensioni dei social media potrebbero essere sia positive che negative e il ML dovrebbe essere in grado di comprenderle entrambe. 'Bel posto. Visiteremo di nuovo.' È una frase positiva mentre "Che posto fantastico era una volta!" Amavamo questo posto!' è negativo e l'annotazione umana può rendere questo processo molto più semplice.

Sfide nell'annotazione dei dati e come superarle
Due sfide principali nell'annotazione dei dati sono il costo e l'accuratezza.
La necessità di dati altamente accurati: Il destino dei progetti AI e ML dipende dalla qualità dei dati annotati. I modelli ML e AI devono essere costantemente alimentati con dati ben classificati che possono addestrare il modello a riconoscere la correlazione tra le variabili.
La necessità di grandi quantità di dati: Tutti i modelli ML e AI prosperano su set di dati di grandi dimensioni: un singolo progetto ML richiede almeno migliaia di elementi etichettati.
La necessità di risorse: I progetti di intelligenza artificiale dipendono dalle risorse, sia in termini di costi, tempo e forza lavoro. Senza nessuno di questi, la qualità del progetto di annotazione dei dati potrebbe andare in tilt.
[Leggi anche: Annotazione video per Machine Learning ]
Migliori pratiche nell'annotazione dei dati
Il valore dell'annotazione dei dati è evidente nel suo impatto sull'esito del progetto AI. Se il set di dati su cui stai addestrando i tuoi modelli ML è pieno di incoerenze, di parte, sbilanciato o danneggiato, la tua soluzione AI potrebbe essere un fallimento. Inoltre, se le etichette sono sbagliate e l'annotazione è incoerente, anche la soluzione AI produrrà previsioni imprecise. Quindi, quali sono le migliori pratiche nell'annotazione dei dati?
Suggerimenti per un'annotazione dei dati efficiente ed efficace
- Assicurati che le etichette dei dati che crei siano specifiche e coerenti con le esigenze del progetto e tuttavia sufficientemente generiche da soddisfare tutte le possibili variazioni.
- Annota grandi quantità di dati necessari per addestrare il modello di machine learning. Maggiore è il numero di dati annotati, migliore sarà il risultato dell'addestramento del modello.
- Le linee guida per l'annotazione dei dati contribuiscono notevolmente a stabilire standard di qualità e garantire la coerenza in tutto il progetto e tra diversi annotatori.
- Poiché l'annotazione dei dati può essere costosa e dipendente dalla manodopera, ha senso controllare i set di dati pre-etichettati dai fornitori di servizi.
- Per facilitare l'accurata annotazione e formazione dei dati, porta le efficienze di human-in-the-loop per portare la diversità e gestire i casi critici insieme alle capacità del software di annotazione.
- Dai priorità alla qualità testando gli annotatori per verificarne la conformità, l'accuratezza e la coerenza.
Importanza del controllo di qualità nel processo di annotazione
 L'annotazione dei dati di qualità è la linfa vitale delle soluzioni AI ad alte prestazioni. Set di dati ben annotati aiutano i sistemi di intelligenza artificiale a funzionare in modo impeccabile, anche in un ambiente caotico. Allo stesso modo, anche il contrario è altrettanto vero. Un set di dati pieno di inesattezze di annotazione genererà soluzioni incoerenti.
L'annotazione dei dati di qualità è la linfa vitale delle soluzioni AI ad alte prestazioni. Set di dati ben annotati aiutano i sistemi di intelligenza artificiale a funzionare in modo impeccabile, anche in un ambiente caotico. Allo stesso modo, anche il contrario è altrettanto vero. Un set di dati pieno di inesattezze di annotazione genererà soluzioni incoerenti.
Pertanto, il controllo di qualità nell'immagine, nell'etichettatura del video e nel processo di annotazione gioca un ruolo significativo nel risultato dell'AI. Tuttavia, mantenere standard di controllo di alta qualità durante tutto il processo di annotazione è una sfida per le aziende di piccole e grandi dimensioni. La dipendenza da vari tipi di strumenti di annotazione e da una forza lavoro di annotazione diversificata può essere difficile da valutare e mantenere la coerenza della qualità.
Mantenere la qualità degli annotatori di dati di lavoro distribuiti o remoti è difficile, soprattutto per coloro che non hanno familiarità con gli standard richiesti. Inoltre, la risoluzione dei problemi o la correzione degli errori può richiedere tempo poiché deve essere identificata in una forza lavoro distribuita.
La soluzione sarebbe formare gli annotatori, coinvolgere un supervisore o fare in modo che più annotatori di dati esaminino e rivedano i colleghi per l'accuratezza dell'annotazione del set di dati. Infine, testare regolarmente gli annotatori sulla loro conoscenza degli standard.
Il ruolo degli annotatori e come selezionare gli annotatori giusti per i tuoi dati
Gli annotatori umani sono la chiave per un progetto di intelligenza artificiale di successo. Gli annotatori di dati assicurano che i dati siano annotati in modo accurato, coerente e affidabile poiché possono fornire contesto, comprendere l'intento e gettare le basi per verità di base nei dati.
Alcuni dati vengono annotati artificialmente o automaticamente con l'aiuto di soluzioni di automazione con un discreto grado di affidabilità. Ad esempio, puoi scaricare centinaia di migliaia di immagini di case da Google e trasformarle in un set di dati. Tuttavia, l'accuratezza del set di dati può essere determinata in modo affidabile solo dopo che il modello ha iniziato a funzionare.
L'automazione automatizzata potrebbe rendere le cose più facili e veloci, ma innegabilmente meno accurate. Il rovescio della medaglia, un annotatore umano può essere più lento e più costoso, ma è più preciso.
Gli annotatori di dati umani possono annotare e classificare i dati in base alla loro esperienza in materia, conoscenza innata e formazione specifica. Gli annotatori di dati stabiliscono accuratezza, precisione e coerenza.
[Leggi anche: Una guida per principianti all'annotazione dei dati: suggerimenti e best practice ]
Conclusione
Per creare un progetto AI ad alte prestazioni, sono necessari dati di addestramento annotati di alta qualità. Mentre l'acquisizione di dati ben annotati in modo coerente potrebbe richiedere tempo e risorse, anche per le grandi aziende, la soluzione sta nel cercare i servizi di fornitori di servizi di annotazione dei dati affermati come Shaip. In Shaip, ti aiutiamo a scalare le tue capacità di intelligenza artificiale attraverso i nostri servizi specialistici di annotazione dei dati, soddisfacendo la domanda del mercato e dei clienti.


