
Il riconoscimento vocale automatico (ASR) ha fatto molta strada. Sebbene sia stato inventato molto tempo fa, non è stato quasi mai utilizzato da nessuno. Tuttavia, il tempo e la tecnologia sono ora cambiati in modo significativo. La trascrizione audio si è sostanzialmente evoluta.
Tecnologie come l'intelligenza artificiale (intelligenza artificiale) hanno potenziato il processo di traduzione da audio a testo per risultati rapidi e accurati. Di conseguenza, anche le sue applicazioni nel mondo reale sono aumentate, con alcune app popolari come Tik Tok, Spotify e Zoom che incorporano il processo nelle loro app mobili.
Quindi esploriamo l'ASR e scopriamo perché è una delle tecnologie più popolari nel 2022.
Che cos'è la sintesi vocale?
La sintesi vocale è una tecnologia potenziata dall'intelligenza artificiale che traduce il parlato umano da una forma analogica a una digitale. Inoltre, la forma digitale dei dati raccolti viene trascritta in un formato di testo.
La sintesi vocale viene spesso confusa con il riconoscimento vocale, che è completamente diverso da questo metodo. Nel riconoscimento vocale, l'obiettivo è identificare i modelli vocali delle persone, mentre, in questo metodo, il sistema cerca di identificare le parole pronunciate.
Nomi comuni di discorso al testo
Questa tecnologia avanzata di riconoscimento vocale è anche popolare e indicata con i nomi:
- Riconoscimento vocale automatico (ASR)
- Il riconoscimento vocale
- Riconoscimento vocale del computer
- Trascrizione audio
- Lettura dello schermo
Comprendere il funzionamento del riconoscimento vocale automatico
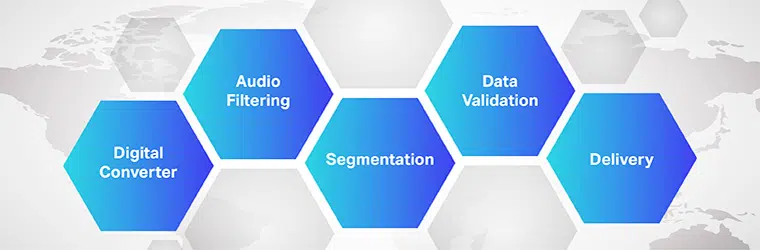
Il funzionamento del software di traduzione da audio a testo è complesso e prevede l'implementazione di più passaggi. Come sappiamo, speech-to-text è un software esclusivo progettato per convertire file audio in un formato di testo modificabile; lo fa sfruttando il riconoscimento vocale.
Processo
- Inizialmente, utilizzando un convertitore analogico-digitale, un programma per computer applica algoritmi linguistici ai dati forniti per distinguere le vibrazioni dai segnali uditivi.
- Successivamente, i suoni rilevanti vengono filtrati misurando le onde sonore.
- Inoltre, i suoni sono distribuiti/segmentati in centesimi o millesimi di secondo e confrontati con i fonemi (Un'unità di suono misurabile per differenziare una parola da un'altra).
- I fonemi vengono ulteriormente eseguiti attraverso un modello matematico per confrontare i dati esistenti con parole, frasi e frasi ben note.
- L'output è in un file di testo o audio basato su computer.
[Leggi anche: Una panoramica completa del riconoscimento vocale automatico]

Quali sono gli usi della sintesi vocale?
Esistono molteplici usi di software di riconoscimento vocale automatico, come
- Ricerca contenuto: La maggior parte di noi è passata dalla digitazione di lettere sui nostri telefoni alla pressione di un pulsante affinché il software riconosca la nostra voce e fornisca i risultati desiderati.
- Servizio Clienti: I chatbot e gli assistenti AI che possono guidare i clienti attraverso i pochi passaggi iniziali del processo sono diventati comuni.
- Sottotitoli in tempo reale: con un maggiore accesso globale ai contenuti, i sottotitoli in tempo reale sono diventati un mercato importante e significativo, spingendo l'ASR in avanti per il suo utilizzo.
- Documentazione elettronica: Diversi dipartimenti amministrativi hanno iniziato a utilizzare l'ASR per adempiere a scopi di documentazione, garantendo una migliore velocità ed efficienza.
Quali sono le principali sfide al riconoscimento vocale?
Annotazione audio non ha ancora raggiunto l'apice del suo sviluppo. Ci sono ancora molte sfide che gli ingegneri stanno cercando di contrastare per rendere efficiente il sistema, ad esempio
- Ottenere il controllo su accenti e dialetti.
- Comprendere il contesto delle frasi pronunciate.
- Separazione dei rumori di fondo per amplificare la qualità dell'input.
- Passaggio del codice a lingue diverse per un'elaborazione efficiente.
- Analizzare i segnali visivi utilizzati nel discorso nel caso di file video.
Trascrizioni audio e sviluppo dell'IA per sintesi vocale
La sfida più grande con il software di riconoscimento vocale automatico è creare il suo output con precisione al 100%. Poiché i dati grezzi sono dinamici e non è possibile applicare un singolo algoritmo, i dati vengono annotati per addestrare l'IA a comprenderli nel giusto contesto.
Per eseguire questo processo, devono essere implementate attività specifiche, come ad esempio:
 Riconoscimento di entità nominative (NER): NER è il processo di identificazione e segmentazione di diverse entità denominate in categorie specifiche.
Riconoscimento di entità nominative (NER): NER è il processo di identificazione e segmentazione di diverse entità denominate in categorie specifiche.- Analisi del sentimento e dell'argomento: Il software che utilizza più algoritmi conduce l'analisi del sentiment dei dati forniti per fornire risultati privi di errori.
 Riconoscimento di entità nominative (NER):
Riconoscimento di entità nominative (NER): - Analisi di intenti e conversazioni: Il rilevamento delle intenzioni mira ad addestrare l'IA a riconoscere l'intenzione di chi parla. Viene utilizzato principalmente per creare chatbot basati sull'intelligenza artificiale.
Conclusione
La tecnologia speech-to-text è in una fase eccezionale al momento. Con più dispositivi digitali che incorporano la ricerca vocale e gli assistenti di controllo nelle loro app, la domanda di trascrizione audio è destinata a salire. Se desideri aggiungere questa straordinaria funzionalità alla tua app, contatta gli esperti di raccolta dati vocali di Shaip per conoscere tutti i dettagli.


