
I sistemi di riconoscimento vocale automatico e gli assistenti virtuali come Siri, Alexa e Cortana sono diventati parti comuni della nostra vita. La nostra dipendenza da loro sta aumentando in modo significativo man mano che diventano più intelligenti. Dall'accensione delle luci all'effettuare chiamate al cambio dei canali TV, sfruttiamo queste tecnologie intelligenti per completare le attività banali.
Tuttavia, ti sei mai chiesto come funzionano questi sistemi di riconoscimento vocale?
Bene, questo blog ti istruirà su alcuni dei fondamenti del riconoscimento vocale automatico. Inoltre, esploreremo il suo funzionamento e come sono costruiti gli assistenti virtuali funzionali come Siri.
Che cos'è il riconoscimento vocale automatico?
Automatic Speech Recognition (ASR) è un software che consente al sistema informatico di convertire il parlato umano in testo, sfruttando molteplici algoritmi di intelligenza artificiale e apprendimento automatico.
Dopo aver convertito e analizzato il comando dato, il computer risponde con un output appropriato per l'utente. L'ASR è stato introdotto per la prima volta nel 1962 e da allora ha migliorato continuamente le sue operazioni e ha ottenuto un'enorme ribalta grazie ad applicazioni popolari come Alexa e Siri.
Qual è il processo per la raccolta dei discorsi per la formazione dei modelli ASR?
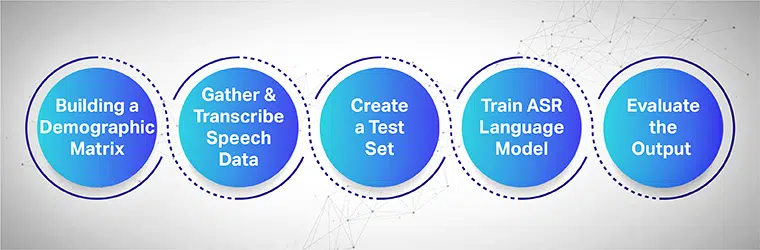
La raccolta vocale mira a raccogliere diverse registrazioni campione da più aree utilizzate per alimentare e addestrare modelli ASR. Il sistema ASR offre la massima efficienza quando vengono raccolti e forniti grandi set di dati di voce e audio al suo sistema.
Per funzionare senza problemi, i set di dati vocali raccolti devono contenere tutti i dati demografici, le lingue, gli accenti e i dialetti target. Il processo seguente mostra come addestrare il modello di apprendimento automatico in più passaggi:
Inizia costruendo una matrice demografica
In primo luogo raccoglie i dati per diversi dati demografici come la posizione, i sessi, la lingua, l'età e gli accenti. Inoltre, assicurati di catturare una varietà di rumori ambientali come il rumore della strada, il rumore della sala d'attesa, il rumore degli uffici pubblici, ecc.
Raccogli e trascrivi i dati del discorso
Il passaggio successivo è la raccolta di campioni audio e vocali umani in base a diverse posizioni geografiche per addestrare il tuo modello ASR. È un passo importante e richiede agli esperti umani di eseguire espressioni lunghe e brevi di parole per ottenere la sensazione genuina della frase e ripetere le stesse frasi con accenti e dialetti diversi.
Crea un set di test separato
Dopo aver raccolto il testo trascritto, il passaggio successivo consiste nell'associarlo ai dati audio corrispondenti. Quindi, segmenta ulteriormente i dati e includi un'affermazione da essi. Ora, dalle coppie di dati segmentati, puoi estrarre dati casuali da un set per ulteriori test.
Allena il tuo modello linguistico ASR
Più informazioni hanno i tuoi set di dati, migliori saranno le prestazioni del tuo modello addestrato all'IA. Pertanto, genera più variazioni di testo e discorsi che hai registrato in precedenza. Parafrasare le stesse frasi usando diverse notazioni vocali.
Valuta l'output e, infine, itera
Infine, misura l'output del tuo modello ASR per correggere le sue prestazioni. Testare il modello rispetto a un set di test per determinarne l'efficienza. In modo appropriato, impegna il tuo modello ASR in un ciclo di feedback per generare l'output desiderato e correggere eventuali lacune.
[Leggi anche: Una panoramica completa del riconoscimento vocale automatico]

Quali sono i diversi casi d'uso del riconoscimento vocale?
La tecnologia di riconoscimento vocale è oggi molto diffusa in molti settori. Alcuni settori che utilizzano questa straordinaria tecnologia sono i seguenti:
 Industria alimentare: I giganti del cibo come Wendy's e McDonald's sono pronti a migliorare le loro esperienze dei clienti utilizzando l'ASR. In molti dei loro punti vendita, hanno implementato modelli ASR completamente funzionanti per prendere gli ordini e passarli ulteriormente alla sezione di cottura per preparare l'ordine del cliente.
Industria alimentare: I giganti del cibo come Wendy's e McDonald's sono pronti a migliorare le loro esperienze dei clienti utilizzando l'ASR. In molti dei loro punti vendita, hanno implementato modelli ASR completamente funzionanti per prendere gli ordini e passarli ulteriormente alla sezione di cottura per preparare l'ordine del cliente.- Telecomunicazione: Vodafone è uno dei maggiori fornitori di telecomunicazioni al mondo. Ha progettato i suoi servizi di assistenza clienti e di inoltro telefonico sfruttando modelli ASR che guidano l'utente a risolvere diverse domande e reindirizzare le chiamate ai dipartimenti interessati.
- Viaggi e trasporti: Google Android Auto o Apple CarPlay sono diventati comuni. La maggior parte delle persone li usa per attivare i sistemi di navigazione, inviare messaggi o cambiare playlist musicali. Tuttavia, con i progressi tecnologici, tali sistemi stanno diventando più raffinati.
BMW Intelligent Personal Assistant lanciato nella sua BMW Serie 3 è molto più intelligente dei normali assistenti vocali. Può consentire ai conducenti di trovare informazioni relative all'auto e di utilizzare l'auto utilizzando i comandi vocali. - Media e intrattenimento: Anche l'industria dei media utilizza l'ASR in molti dei suoi progetti. Youtube ha lanciato un assistente basato sull'intelligenza artificiale che genera sottotitoli automatici dal vivo. Mentre parli sullo schermo, l'assistente fornirà i sottotitoli per rendere il video accessibile a un gruppo più ampio di utenti di Youtube.
 Industria alimentare: I giganti del cibo come Wendy's e McDonald's sono pronti a migliorare le loro esperienze dei clienti utilizzando l'ASR. In molti dei loro punti vendita, hanno implementato modelli ASR completamente funzionanti per prendere gli ordini e passarli ulteriormente alla sezione di cottura per preparare l'ordine del cliente.
Industria alimentare: I giganti del cibo come Wendy's e McDonald's sono pronti a migliorare le loro esperienze dei clienti utilizzando l'ASR. In molti dei loro punti vendita, hanno implementato modelli ASR completamente funzionanti per prendere gli ordini e passarli ulteriormente alla sezione di cottura per preparare l'ordine del cliente. Telecomunicazione: Vodafone è uno dei maggiori fornitori di telecomunicazioni al mondo. Ha progettato i suoi servizi di assistenza clienti e di inoltro telefonico sfruttando modelli ASR che guidano l'utente a risolvere diverse domande e reindirizzare le chiamate ai dipartimenti interessati.
Telecomunicazione: Vodafone è uno dei maggiori fornitori di telecomunicazioni al mondo. Ha progettato i suoi servizi di assistenza clienti e di inoltro telefonico sfruttando modelli ASR che guidano l'utente a risolvere diverse domande e reindirizzare le chiamate ai dipartimenti interessati. Viaggi e trasporti: Google Android Auto o Apple CarPlay sono diventati comuni. La maggior parte delle persone li usa per attivare i sistemi di navigazione, inviare messaggi o cambiare playlist musicali. Tuttavia, con i progressi tecnologici, tali sistemi stanno diventando più raffinati.
Viaggi e trasporti: Google Android Auto o Apple CarPlay sono diventati comuni. La maggior parte delle persone li usa per attivare i sistemi di navigazione, inviare messaggi o cambiare playlist musicali. Tuttavia, con i progressi tecnologici, tali sistemi stanno diventando più raffinati. Media e intrattenimento: Anche l'industria dei media utilizza l'ASR in molti dei suoi progetti. Youtube ha lanciato un assistente basato sull'intelligenza artificiale che genera sottotitoli automatici dal vivo. Mentre parli sullo schermo, l'assistente fornirà i sottotitoli per rendere il video accessibile a un gruppo più ampio di utenti di Youtube.
Media e intrattenimento: Anche l'industria dei media utilizza l'ASR in molti dei suoi progetti. Youtube ha lanciato un assistente basato sull'intelligenza artificiale che genera sottotitoli automatici dal vivo. Mentre parli sullo schermo, l'assistente fornirà i sottotitoli per rendere il video accessibile a un gruppo più ampio di utenti di Youtube.
[Leggi anche: Che cos'è la tecnologia Speech-To-Text e come funziona]
Come può aiutare Shaip?
Shaip è uno dei principali servizi di formazione sull'IA che detiene competenze in molteplici aree dell'IA e del machine learning. Possono aiutarti a creare il tuo set di dati che potrebbe essere utilizzato per diverse applicazioni e progetti.
Alcuni dei servizi forniti da Shaip sono:
- Riconoscimento vocale automatizzato (ASR)
- Raccolta di discorsi con script
- Transcreazione
- Raccolta di discorsi spontanei
- Raccolta di espressioni/Parole di risveglio,
- Sintesi vocale (TTS)
Puoi avvalerti di questi servizi per ottenere i migliori risultati per i tuoi progetti basati sull'intelligenza artificiale. Scopri di più su questi servizi contattando il nostro team di esperti oggi stesso!


